- Mobile Data Collection Using CSPro
- Session 01: Overview of CSPro, Dictionary and Forms
- Session 02: Skips and Prefills
- Session 03: Consistency Checks
- Session 04: More Logic in Data Entry, Rosters, Subscripts and Loops
- Session 05: CAPI Features
- Session 06: Functions, Lookup Files, Navigation & System Control
- Session 07: Multimedia & GPS
- Session 08: Menu Programs
- Session 09: Synchronization
- Session 10: Batch Edit and Export
Session 10: Batch Edit and Export
At the end of this session participants will be able to:
- Implement consistency checks in a batch edit application
- Use batch edit to add calculated variables and recoded variables
- Use batch edit to convert checkbox values to yes/no variables for analysis
- Use the Export Data tool to take data from CSPro to other software packages
Creating a Batch Edit Application
A batch edit application is like a data entry application but without the forms. It is meant to be run after data entry to detect and fix problems in the data file. A batch edit application takes an input data file and runs logic on it. It generates both a report, called a listing file, and optionally an output data file which is a modified version of the input file. A batch edit application never changes the input file.To create a batch edit application you choose File->New from CSPro and choose Batch Edit Application. You then choose a dictionary. This is usually the same dictionary that you used for data entry.
The user interface for working with batch applications is similar to the one for working with data entry applications except that there are no forms. Instead there is a tab in the tree one left side of the window for edits. Just like in data entry, you add logic to PROCS. Instead of running interactively, all the error messages are written out to a log file for review after the whole program has run.
Checking for Errors
To add consistency checks we proceed just as we did in our data entry application by adding logic to the appropriate PROC. Let's start with a simple check that the age of first marriage is not greater than the age.Next we run the application but first we need a test data file. You can use the file Popstan2020Raw.csdb. Run the application against this test data. After the application runs, we see the log file. The log file reports that we have a case where this error exists.
Process Messages
*** Case [3691141112] has 1 messages (0 E / 0 W / 1U)
U -20 Age at first marriage greater than age
User unnumbered messages:
Line Freq Pct. Message text Denom
---- ---- ---- ------------ -----
20 1 - Age at first marriage greater than age -
CSPRO Executor Normal End
To figure out what the problem is we can open up the problem case in data entry. The printout in the listing file contains the case identifiers which we can use to find the case. You can copy the case ID from the listing file and use it with Find Case on the Edit menu in CSEntry.
Getting Summary Information
If you add summary after the errmsg statement, the individual error cases will not be written to the listing file. With summary, only the total number of times each error is encountered is written to the file. This can be helpful when working with large data files that have a lot of errors making the listing file very large.Now when we run the application, the listing file no longer contains the individual cases where the errors occurred.
User unnumbered messages:
Line Freq Pct. Message text Denom
---- ---- ---- ------------ -----
20 1 - Age at first marriage greater than age -
CSPRO Executor Normal End
If you add a denominator using the denom keyword, CSPro will calculate the percentage of cases where the error occurred. The denominator to use depends on what is being counted. In our case it is the total number of household members with age 10 or above and marital status married, divorced or widowed. We can calculate that total as part of our batch edit program.
PROC GLOBAL
numeric numHHMembers10AndOverEverMarried = 0;
PROC AGE_AT_FIRST_MARRIAGE
if AGE >= 10 and MARITAL_STATUS in 2:4 then
numHHMembers10AndOverEverMarried = numHHMembers10AndOverEverMarried + 1;
// Check for age at first marriage less than current age
if AGE_AT_FIRST_MARRIAGE > AGE then
errmsg("Age at first marriage greater than age") summary
denom = numHHMembers10AndOverEverMarried;
endif;
endif;
numeric numHHMembers10AndOverEverMarried = 0;
PROC AGE_AT_FIRST_MARRIAGE
if AGE >= 10 and MARITAL_STATUS in 2:4 then
numHHMembers10AndOverEverMarried = numHHMembers10AndOverEverMarried + 1;
// Check for age at first marriage less than current age
if AGE_AT_FIRST_MARRIAGE > AGE then
errmsg("Age at first marriage greater than age") summary
denom = numHHMembers10AndOverEverMarried;
endif;
endif;
Now when we run the program we see that 0.2% of the individuals 10 and above who where ever married have an age at first marriage greater than their age.
User unnumbered messages:
Line Freq Pct. Message text Denom
---- ---- ---- ------------ -----
20 1 0.2 Age at first marriage greater than age 463
CSPRO Executor Normal End
Correcting Errors
In addition to using batch edit to find errors you can also use it to correct problems by modifying variables in your logic. Let's simply cap the age at first marriage to never be greater than the age.When we run this time we will specify an output file: Popstan2020Edited.csdb. The changes we make will only be made to the output file. We can then rerun the batch application on the output file and make sure that we don't have any error messages.
Instead of just assigning the value of AGE_FIRST_MARRIAGE we can use the impute command which does the assignment just like "=" but also generates a nice report showing the values that were imputed.
The imputation report will be opened in Text Viewer after you run the batch application but to see it you will need to go to the Window menu and choose the file that ends in ".frq.lst".
IMPUTE FREQUENCIES Page 1
________________________________________________________________________________
Imputed Item AGE_AT_FISRT_MARRIAGE: Age at first marriage - all occurrences
_____________________________ _____________
Categories Frequency CumFreq % Cum %
_______________________________ _____________________________ _____________
40 1 1 100.0 100.0
_______________________________ _____________________________ _____________
TOTAL 1 1 100.0 100.0
Adding Calculated Variables
It is often useful to add additional variables to your data file after data collection that are computed from the collected variables. For example, let's add a yes/no/don't know variable to the household record that determines if the household is headed by a child. First we add the new variable CHILD_HEADED_HOUSEHOLD to the dictionary (at the end of the housing record so that we do not mess up our existing data). Then we add logic to the PROC of our new variable to impute the value. A household is headed by a child if the age of the head is less than 18.PROC CHILD_HEADED_HOUSEHOLD
// Set calculated variable child headed based on age of head
if AGE(1) < 18 then
// Head under 18, child headed
impute(CHILD_HEADED_HOUSEHOLD, 1);
elseif AGE(1) = 999 then
// Head age unknown
impute(CHILD_HEADED_HOUSEHOLD, 9);
else
// Head over 18, not child headed
impute(CHILD_HEADED_HOUSEHOLD, 2);
endif;
// Set calculated variable child headed based on age of head
if AGE(1) < 18 then
// Head under 18, child headed
impute(CHILD_HEADED_HOUSEHOLD, 1);
elseif AGE(1) = 999 then
// Head age unknown
impute(CHILD_HEADED_HOUSEHOLD, 9);
else
// Head over 18, not child headed
impute(CHILD_HEADED_HOUSEHOLD, 2);
endif;
Run the program and look at the imputation report to see how many child headed households are in our data set.
Converting Checkboxes to Yes/No
The checkbox makes a nice interface but the resulting data is a string that is hard to interpret and deal with in other software. To make it easier to use for export we can convert from the checkbox to a repeating item with yes/no options. Let's convert the LANGUAGES_SPOKEN field to a series of yes/no variables. Create new yes/no items for each language at the end of the individual record. Add value sets with Yes – 1 and No – 2.For each of these new variables we want to set the value to yes if the corresponding language is checked in LANGUAGES_SPOKEN. What function do we use to determine if an item in a checkbox field is checked? As before we use pos().
PROC LANGUAGE_ENGLISH_SPOKEN
if pos("A", LANGUAGES_SPOKEN) > 0 then
LANGUAGE_ENGLISH_SPOKEN = 1;
else
LANGUAGE_ENGLISH_SPOKEN = 2;
endif;
PROC LANGUAGE_FRENCH_SPOKEN
if pos("B", LANGUAGES_SPOKEN) > 0 then
LANGUAGE_FRENCH_SPOKEN = 1;
else
LANGUAGE_FRENCH_SPOKEN = 2;
endif;
PROC LANGUAGE_SPANISH_SPOKEN
if pos("C", LANGUAGES_SPOKEN) > 0 then
LANGUAGE_SPANISH_SPOKEN = 1;
else
LANGUAGE_SPANISH_SPOKEN = 2;
endif;
if pos("A", LANGUAGES_SPOKEN) > 0 then
LANGUAGE_ENGLISH_SPOKEN = 1;
else
LANGUAGE_ENGLISH_SPOKEN = 2;
endif;
PROC LANGUAGE_FRENCH_SPOKEN
if pos("B", LANGUAGES_SPOKEN) > 0 then
LANGUAGE_FRENCH_SPOKEN = 1;
else
LANGUAGE_FRENCH_SPOKEN = 2;
endif;
PROC LANGUAGE_SPANISH_SPOKEN
if pos("C", LANGUAGES_SPOKEN) > 0 then
LANGUAGE_SPANISH_SPOKEN = 1;
else
LANGUAGE_SPANISH_SPOKEN = 2;
endif;
The remaining languages follow the same pattern.
The Export Data Tool
The CSPro Export Data tool is available from the Tools menu. When you first start Export Data you are prompted to provide a data dictionary. Choose the Popstan2020 dictionary. From the main export screen, you can choose which records/variables to export using the checkboxes next to each one. To start with let's just pick the ID items and the first few fields from section F. At the bottom of the export window you can choose the file format to export to. For this exercise we will choose CSV which can be easily opened in Excel. To run the export, click on the traffic light. You are prompted to choose the data file. We will use the Popstan2020Edited.csdb data file. Finally, you are prompted for the name(s) of the exported files. Once the export completes the exported files are displayed in Text Viewer. Let's open them in Excel and see what we have. Note that each household is saved in a separate line in the Excel file.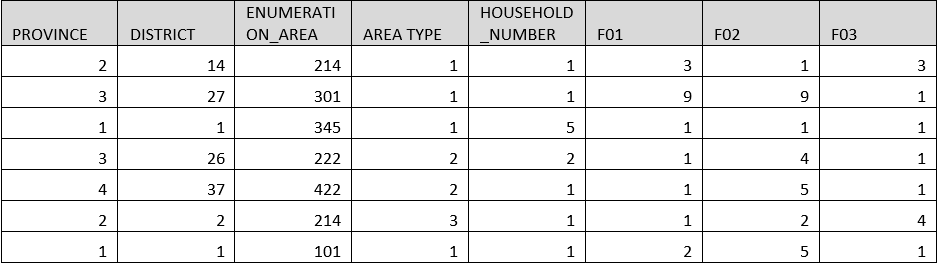
Exporting Repeating Records
Let's try exporting a few fields from section B: line number, name and sex. Notice for each variable we exported we get 50 columns. Why is that? We are getting one column for each record occurrence. CSPro is still exporting each household on a single row and since there are up to 50 people in the household it generates 50 columns for each variable. Even empty occurrences are still generating columns in the spreadsheet.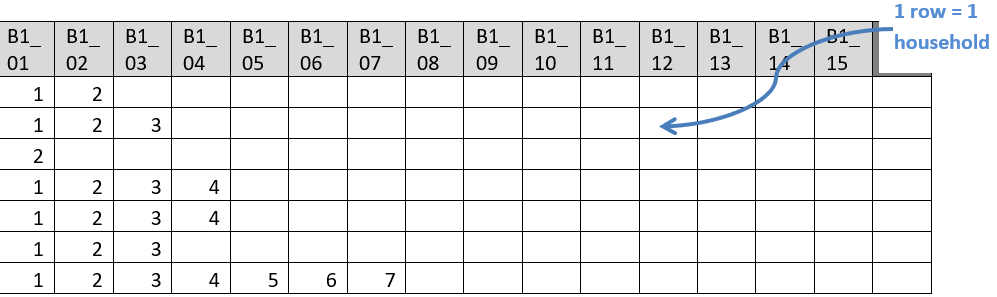
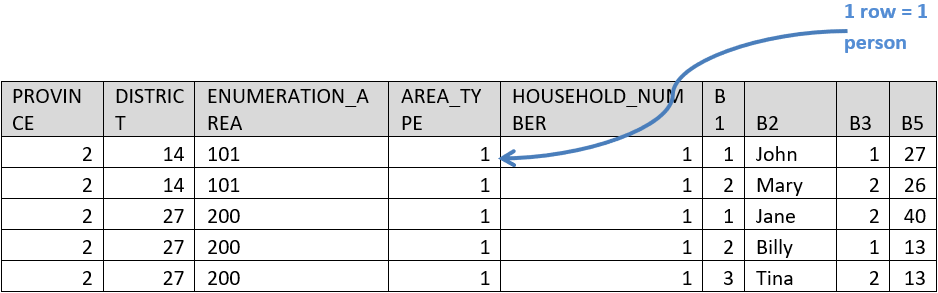
Having a column for each occurrence can complicate working with the data. For example, in this file it is rather tough to do something as simple as count the total number of people. If instead of choosing the default setting of putting multiple record occurrences in a single row (the All in One Record setting) try selecting As Separate Records. Now we get each person in the household in a separate row. It is important to include the household ID items when doing this so that it is clear which people are in which household.
Exporting Multiple Record Types
Now let's try exporting the first few items from both the person record (B) and the deaths record (E). With our current settings, Export Data warns us that only items from the first record will be exported. Why? The problem is that if you put each record in its own row then some rows would have household members on them and others would have deaths on them but then the columns would not match.The solution is to export each record in a separate file by selecting Multiple Files (one for each record type) under Number of Files Created. Doing this generates two files: PERSON.csv which contains the household members and DEATHS.csv which contains the deaths.
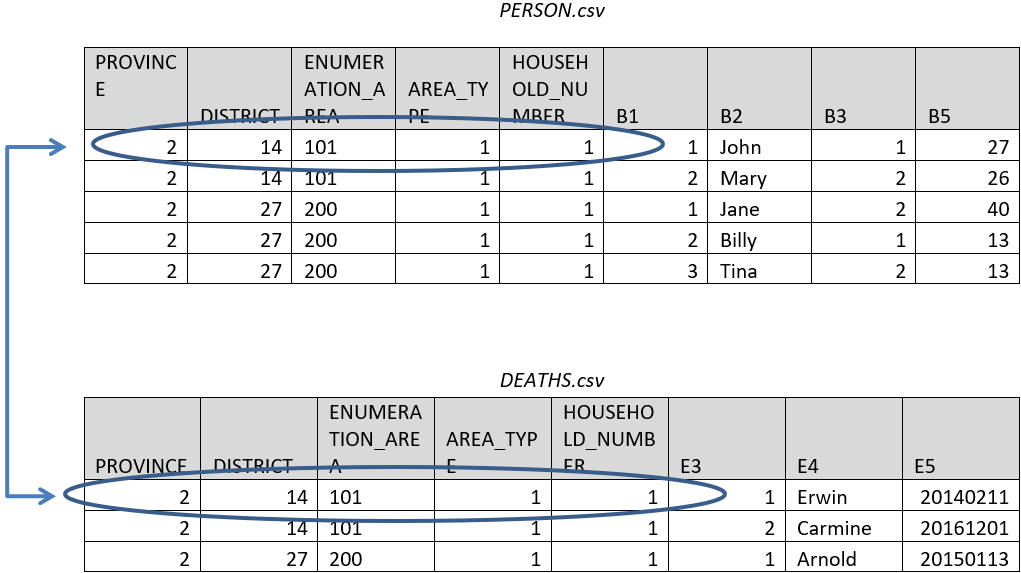
The households in these two files can be linked together based on the ID items.
It also possible to have Export Data join together single and multiple records. If you select this option, then one file will be generated for each record with multiple occurrences and the selected columns for all the selected singly occurring records will be added to each row in each of the exported files. For example, if we choose the tenure status (F06) and type of main dwelling (F03) from the single record housing and also choose the first few items from the person record then F06 and F03 will be added to each of the two exported files: PERSON.csv and DEATHS.csv.
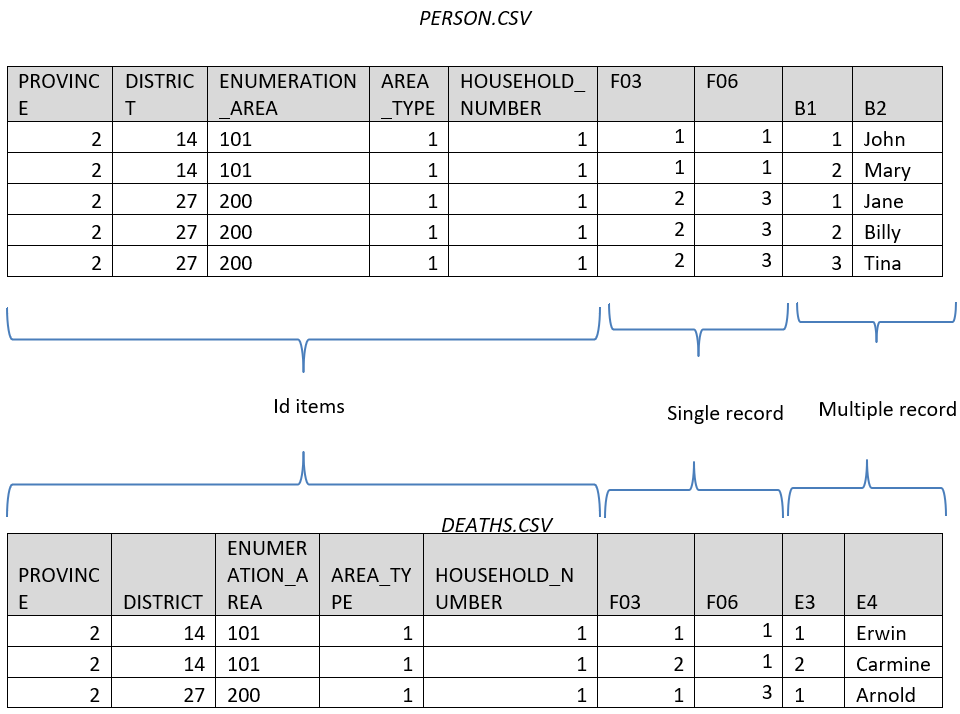
It is not possible to join multiple records to other multiple records from export.
Note that in some cases it may be easier to do the export of the single and multiple records without joining and then do the join in the software that you have imported the data into.
Importing Data into SAS, SPSS, Stata and R
When exporting data to statistical packages, CSPro generates both a data file and script to run inside the statistical software itself to run the import. For details on how to run this script for each package, see the helps for Export Data and look under "Loading Exported Data Into…".Saving your Export Specification
You can save your export settings as CSPro export specification file (.exf). You can later double click on this file or open it from the Export Data Tool to retrieve all the selections that were made.Exercises
- Modify the batch edit application to add a check for someone with relationship of spouse but marital status that is not married. Print a message for each case found. This should be done in the batch edit application NOT in the data entry application.
- Modify the batch edit application to add a check that the total number of rooms (F01) is greater than the number of bedrooms (F02)
- Modify the batch edit application to add a check that the type of main dwelling (F03) is consistent with the total numbers of each dwelling type in F05. For example, if the main dwelling in F03 is detached house then the total number of detached houses in F05 must not be zero.
- Modify the batch edit application to convert the disabilities (B11) from alpha (used for checkboxes) to a set of numeric yes/no variables. Create the new variables in the dictionary and write logic to set the value of each of the new variables based on the selections in B11.
- Using the test data, export the household members along with the ID items to the package of your choice (Excel, SPSS, Stata, SAS or R). Use that package to determine the total number of people by sex (total, males, females) and also the number of people by sex for district 01.
- Export the deaths record and the person record along with the ID items into the package of your choice. You should export all the records at once, not one by one. How many households have more than one death? How many households have children under 5 years of age?