- Mobile Data Collection Using CSPro
- Session 01: Overview of CSPro, Dictionary and Forms
- Session 02: Skips and Prefills
- Session 03: Consistency Checks
- Session 04: More Logic in Data Entry, Rosters, Subscripts and Loops
- Session 05: CAPI Features
- Session 06: Functions, Lookup Files, Navigation & System Control
- Session 07: Multimedia & GPS
- Session 08: Menu Programs
- Session 09: Synchronization
- Session 10: Batch Edit and Export
Session 05: CAPI Features
At the end of this session participants will be able to:
- Add question text and help text
- Add fills in question text
- Use multiple languages in question text, error messages and the dictionary
- Use occurrence labels as fills in question text
- Use setcaselabel to customize the case listing
- Use dynamic value sets
Question Text
We can add text to each question in our survey by clicking on "CAPI Questions" in the toolbar. This allows us to enter literal question text for the questionnaire that the interviewer will read verbatim. Additionally, we can add interviewer instructions. Let's start with the first few questions in section B.For RELATIONSHIP, enter "What is (name's) relationship to the head of the household?" For SEX enter "Is (name) a male or a female?". Run the application on Windows and then on mobile to see how the question text is displayed.
In addition to the text, we can add instructions to the interviewer. For example for AGE we can have:
How old is (name)?
Followed by the instruction:
Enter age in completed years ("0" for children less than one year old)
To make it clear to the interviewer that this is an instruction, we use italics to distinguish it from the question. We can also use different colors and fonts as well. You can use whatever scheme you like as long as it is consistent throughout the application.
If you have your question text in Word or Excel you can copy and paste into CSPro and it will preserve the formatting.
Help Text
In addition to question text, we can provide additional instructions to the interviewer as "help text". Help text is not shown by default but can be displayed by using the F2 key on Windows or tapping the help icon next to the question text on Mobile.Let's add the following help text to the NAME field in section B:
Include all persons living in this house who have common arrangements for cooking and dining.
Run the application on both Android and Windows and see how the help text is displayed.
Fills in Question Text
It is possible to have the question include the values of dictionary variables. For example, for SEX, instead of asking "Is (name) a male or a female?" we can include the respondents name by using ~~NAME~~ inside the question text. At runtime, this will be replaced by the contents of the variable NAME.Let's change the text for RELATIONSHIP, SEX and AGE to use ~~NAME~~ in place of "(name)".
Conditional Question Text
Sometimes, the question text will be completely different depending on other factors and using fill variables is not sufficient to implement the differences. For example, the question text for the NAME field should really be:What is the name of the head household? – for the first row of the roster
What is the name of the next member of the household? – for the remaining rows of the roster.
We can implement this using the conditions window underneath the question text window. By default, this window contains a single empty condition. Right-clicking on the conditions lets you add a new condition. Let's modify the first condition to be curocc() = 1 and then add a second condition curocc() > 1. Now we have two different question texts, one that will be shown for the first occurrence and the other that will be shown for the rest. Edit these two questions texts as above and test it to verify that it works.
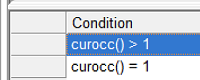
It is possible to specify any logic expression in the condition column to determine whether or not to display the text. For example setting the condition to "SEX=1" will display the question text only for males.
Supporting Multiple Languages
It is possible to add question text, dictionary labels and error messages in multiple languages.Multiple Languages for Question Text
To have multiple languages for question text you first need to define the languages. This is done from the CAPI Options Menu. Select "Define CAPI Languages". This will bring up the "Language" dialog box. Click on "Add" to add a language, specify the name and label to use for the language and click "OK". The label is what the interviewer will see when choosing a language and the name is what will be used in logic to refer to the language. The name should be a two letter abbreviation for the language from the ISO 639-1 standard such as EN, FR and ES. While you may use any language name, if you use one of the ISO 639-1 codes then CSPro will automatically set the language of your application to the language set in the system settings of your mobile device.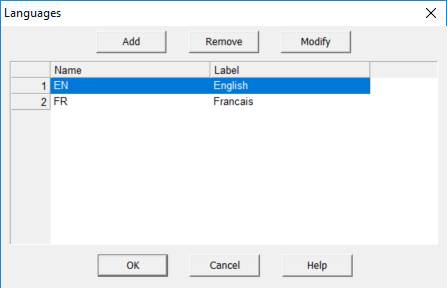
When creating question text, you enter the question text for each language specified. Let's look at the question text for the "Sex" item. There is a Drop Down menu for the languages we specified in the above steps. We select the language and then enter the question text in that language.
For example, to add French translations for the sex, relationship and age questions we would enter:
Est-ce que ~~NAME~~ est masculin ou feminin?
Quel est le lien de parenté de ~~NAME~~ avec le chef de ménage?
Quel est l'âge de ~~NAME~~?
Entrez l'âge en années révolues (entrez 0 pour les enfants âgés de moins de 1 an). Si inconnu entrez 999.
Now that you have created the question text in the specified languages, they can be selected during data entry.
In Windows, we can go to the "Options" Menu and select "Change Language" and a menu of the languages we defined will be displayed. Click on the desired language and the question text will be displayed in that language. On mobile devices you will find "Change Language" on the menu during data entry.
In Windows, we can go to the "Options" Menu and select "Change Language" and a menu of the languages we defined will be displayed. Click on the desired language and the question text will be displayed in that language. On mobile devices you will find "Change Language" on the menu during data entry.
Multiple Languages for Dictionary Items
To have multiple language in value sets, you first need to define the languages. This is similar to the process we did to define multiple languages for question text; however, for dictionary items you define languages from the Edit menu of the dictionary. Make sure you are in the dictionary editor (you may need to click on the little blue book in the toolbar) and choose "Edit" and then "Languages". This dialog is identical to the one used for adding languages to question text. You should make sure to use the same names and labels for languages in this dialog as you entered for question text.Once you have added additional languages to the dictionary you will see a language dropdown on the toolbar. To add a translation for a dictionary label or value set label, choose the language in the dropdown and edit the label as you normally would. This will set the label for the language you chose.
Multiple Language Error Messages
To add translations of text specified in program logic, such as arguments to errmsg(), we can provide translations in the message file. To do this we add the messages to the messages tab at the bottom of the logic editor. Instead of putting the message text in the logic we tag each message with a number and use that number in the logic. In the message tab we list the message numbers followed by the message text. This allows us to supply multiple versions of the message; one for each language. Mark different languages in the file using "Language=" followed by the language name./* Application 'POPSTAN2020' message file generated by CSPro */
Language=EN
100 Head of household must be at least 15 years old
101 Correct age
102 Correct relationship
Language=FR
100 Le chef de menage doit avoir au moins 15 ans.
101 Corriger l'age
102 Corriger le lien de parente
Language=EN
100 Head of household must be at least 15 years old
101 Correct age
102 Correct relationship
Language=FR
100 Le chef de menage doit avoir au moins 15 ans.
101 Corriger l'age
102 Corriger le lien de parente
In the logic you can pass the message number directly to errmsg(). Inside the select clause, however, you will need to use tr() or maketext() around the message number.
Now when we run the application with the language set to French and encounter the error, it will show the French text.
You can also use a separate message file for each language. To add an additional message file, use "Add files" from the files menu and enter the name of the message file next to "External Message File".
Group exercise
Add the question text and the French translations for the question text, labels, value sets and error messages for marital status (B13).Using Occurrence Labels in Question Text
We have the following occurrence labels for the housing unit types in question F05.- Traditional round hut
- Detached house
- Semi-detached house
- Flat/apartment
- Improvised (kiosk/container)
We can use these occurrence labels in the question text for F05:
How many ~~getocclabel()~~ units are in this household?
Anytime you use ~~getocclabel()~~ in question text it is replaced by the occurrence label of the current occurrence. With the above, the question text for the first occurrence will be "How many traditional round hut units are in this household?" and the text for the second occurrence will be "How many detached house units are in this household?" …
Case Labels
By default, the case listing screen shows the ID items concatenated together. This is not very easy for an interviewer to read. You can customize the case listing for a case using the setcaselabel command. As an example let's set the case label to the string "province-district-ea-household number: name of head of household". Since we need to have the name of the head of household to do this, we can add it in the postproc of NAME. In order to format the case label from the variables we can use the function maketext() which works like errmsg() but returns a string instead of displaying it on the screen.PROC NAME
if curocc() = 1 then
// Set label for case in case listing to an easier to read format.
// We do this when we first get the name of the head.
string caseLabel = maketext("%d-%02d-%03d-%03d: %s",
PROVINCE, DISTRICT, ENUMERATION_AREA,
HOUSEHOLD_NUMBER, strip(NAME));
setcaselabel(POPSTAN2020_DICT, caseLabel);
endif;
if curocc() = 1 then
// Set label for case in case listing to an easier to read format.
// We do this when we first get the name of the head.
string caseLabel = maketext("%d-%02d-%03d-%03d: %s",
PROVINCE, DISTRICT, ENUMERATION_AREA,
HOUSEHOLD_NUMBER, strip(NAME));
setcaselabel(POPSTAN2020_DICT, caseLabel);
endif;
The %02d and %03d tell CSPro to format the numbers with 2 and 3 zero-filled decimal digits respectively. If DISTRICT is 1 this will result in "001" instead of just "1". The sizes 2 and 3 are based on the lengths of these variables in the dictionary. Instead of using %d we can use %v which will automtically use the length and zero-fill setting of the variables from the dictionary to format the values.
PROC NAME
if curocc() = 1 then
// Set label for case in case listing to an easier to read format.
// We do this when we first get the name of the head.
string caseLabel = maketext("%v-%v-%v-%v: %s",
PROVINCE, DISTRICT, ENUMERATION_AREA,
HOUSEHOLD_NUMBER, strip(NAME));
setcaselabel(POPSTAN2020_DICT, caseLabel);
endif;
Now after entering a case we have a much friendlier case listing:if curocc() = 1 then
// Set label for case in case listing to an easier to read format.
// We do this when we first get the name of the head.
string caseLabel = maketext("%v-%v-%v-%v: %s",
PROVINCE, DISTRICT, ENUMERATION_AREA,
HOUSEHOLD_NUMBER, strip(NAME));
setcaselabel(POPSTAN2020_DICT, caseLabel);
endif;
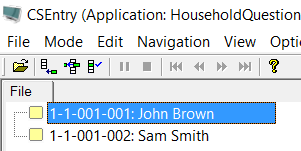
Note that setcaselabel only works with data files of type CSPro DB.
Dynamic Value Sets
It is often useful to change the value set for a question from logic. This can be done using the command setvalueset. Let's start with a simple example. Currently our value set for relationship in section B has labels like "Son/Daughter" and "Brother/Sister" to allow for both genders. However, when we show the relationship value set we already know the gender of the household member so we could show "Son" for males and "Daughter" for females. To do this we create two new value sets for relationship in the dictionary: RELATIONSHIP_MALE and RELATIONSHIP_FEMALE. Then we can use logic to choose between the value sets depending on the value of SEX. Which proc do we do that in? We do that in the onfocus of RELATIONSHIP since we need to use it when we are in that field. The onfocus is called every time the field is entered. We cannot do this in the preproc since the preproc is not triggered when moving backwards through the questions.PROC RELATIONSHIP
onfocus
// Show male or female version of value set depending on sex of the person.
if SEX = 1 then
setvalueset(RELATIONSHIP, RELATIONSHIP_MALE);
else
setvalueset(RELATIONSHIP, RELATIONSHIP_FEMALE);
endif;
onfocus
// Show male or female version of value set depending on sex of the person.
if SEX = 1 then
setvalueset(RELATIONSHIP, RELATIONSHIP_MALE);
else
setvalueset(RELATIONSHIP, RELATIONSHIP_FEMALE);
endif;
Dynamic Value Sets from a Roster
For question A11, line number of respondent, we would like to create a value set from the names and line numbers of the eligible household members. For this to work correctly we will need to ask A11 after entering the names and ages in the household members rosters. Create a new numeric variable in the dictionary for A11 and place it on the household members form after the roster.We will fill in the ValueSet object with names and line numbers of the eligible members in the household. According the specification, only household members 12 and over can be respondents. For example, if we have the following household:

We would fill in the ValueSet object as follows:
| Subscript | Codes | Labels |
|---|---|---|
| 1 | 1 | John Brown |
| 2 | 2 | Mary Brown |
| 3 | 4 | Jane Brown |
To create the value set from the household roster we need the second form of setvalueset that takes a ValueSet object. This will allow us to create the list of names in logic instead of in the dictionary.
First, we need to declare a ValueSet object. A ValueSet object is also a variable like a string or numeric but instead of holding just a single value it can hold and entire value set.
We can add values to the value set by calling the function eligibleMembersVSet.add(). The "." between "eligibleMembersVSet" and "add" tells CSPro to apply the add operation to the ValueSet before the "." which in this case is the ValueSet named eligibleMembersVSet. For example to add John Brown to the value set we would do the following:
eligibleMembersVSet.add("John Brown", 1);
So to build our value set we need to call add for each member of the household 12 and over.
eligibleMembersVSet.add("John Brown", 1);
eligibleMembersVSet.add("Mary Brown", 2);
eligibleMembersVSet.add("Jane Brown", 4);
eligibleMembersVSet.add("Mary Brown", 2);
eligibleMembersVSet.add("Jane Brown", 4);
To make this work for any household we need to call add in loop over the household members.
PROC RESPONDENT_LINE_NUMBER
onfocus
// Create the value set for respondent from all household members 12 and over
ValueSet eligibleMembersVSet;
do numeric indexRoster = 1 while indexRoster <= totocc(HOUSEHOLD_MEMBERS_ROSTER)
if AGE(indexRoster) >= 12 then
eligibleMembersVSet.add(NAME(indexRoster),indexRoster);
endif;
enddo;
setvalueset(RESPONDENT_LINE_NUMBER, eligibleMembersVSet);
onfocus
// Create the value set for respondent from all household members 12 and over
ValueSet eligibleMembersVSet;
do numeric indexRoster = 1 while indexRoster <= totocc(HOUSEHOLD_MEMBERS_ROSTER)
if AGE(indexRoster) >= 12 then
eligibleMembersVSet.add(NAME(indexRoster),indexRoster);
endif;
enddo;
setvalueset(RESPONDENT_LINE_NUMBER, eligibleMembersVSet);
Finally, make sure to set the capture type of the field to "Radio Button" in the field properties for RESPONDENT_LINE_NUMBER.
As a second example we will implement the dynamic value set for mother line number (B10). For this value set we only show females in the household over 12 and don't allow a woman to be her own mother.
// Create value set from women over 12 in household roster
numeric indexRoster;
ValueSet motherVSet;
do numeric indexRoster = 1 while indexRoster <= totocc(HOUSEHOLD_MEMBERS_ROSTER)
if SEX(indexRoster) = 2 and AGE(indexRoster) > 12 and indexRoster <> curocc() then
motherVSet.add(NAME(indexRoster),indexRoster);
endif;
enddo;
numeric indexRoster;
ValueSet motherVSet;
do numeric indexRoster = 1 while indexRoster <= totocc(HOUSEHOLD_MEMBERS_ROSTER)
if SEX(indexRoster) = 2 and AGE(indexRoster) > 12 and indexRoster <> curocc() then
motherVSet.add(NAME(indexRoster),indexRoster);
endif;
enddo;
We also need to include the codes for non-resident and deceased in the value set.
motherVSet.add("Non-resident", 87);
motherVSet.add("Deceased", 88);
motherVSet.add("Deceased", 88);
Finally we need to apply the value set to the field.
setvalueset(MOTHER_LINE_NUMBER, motherVSet);
Dynamic Value Sets from Checkboxes
Question B16 (primary language) should only show a subset of the languages chosen in B15 (languages spoken). We can do this using a dynamic value set as well. The trick is that since B15 uses checkboxes it will have alpha codes (A, B, C…) while B16 will have numeric codes (1,2,3…) so we need to convert from numeric to alpha to determine if a given language was selected. We could do this with a series of if then else statements but an easier approach is to use the string "ABCDEFGH" to convert from numeric to alpha by looking up the character at the position of the numeric code. For example, numeric code 1 would give us the character at the first position: A. Numeric code 2 would give us the character at position 2, B etc…PROC MAIN_LANGUAGE
onfocus
// Create value set from items selected in languages spoken
// Used to translate from checkbox (alpha codes) to numeric codes
string languageCheckboxCodes = "ABCDEFGH";
ValueSet languageVSet = MAIN_LANGUAGE_VS1;
// Loop through the numeric codes 1-8 and add each selected
// to value set
do numeric languageNumericCode = 1 while languageNumericCode <= 8
// Convert the numeric code to the checkbox alpha code
// by looking it up in the string.
string languageCheckboxCode = languageCheckboxCodes[languageNumericCode:1];
// Check if the language is selected in the checkbox field
if pos(languageCheckboxCode, LANGUAGES_SPOKEN) = 0 then
// Language is not selected. Remove it from the value set.
languageVSet.remove(languageNumericCode);
endif;
enddo;
// Modify value set
setvalueset(MAIN_LANGUAGE, languageVSet);
onfocus
// Create value set from items selected in languages spoken
// Used to translate from checkbox (alpha codes) to numeric codes
string languageCheckboxCodes = "ABCDEFGH";
ValueSet languageVSet = MAIN_LANGUAGE_VS1;
// Loop through the numeric codes 1-8 and add each selected
// to value set
do numeric languageNumericCode = 1 while languageNumericCode <= 8
// Convert the numeric code to the checkbox alpha code
// by looking it up in the string.
string languageCheckboxCode = languageCheckboxCodes[languageNumericCode:1];
// Check if the language is selected in the checkbox field
if pos(languageCheckboxCode, LANGUAGES_SPOKEN) = 0 then
// Language is not selected. Remove it from the value set.
languageVSet.remove(languageNumericCode);
endif;
enddo;
// Modify value set
setvalueset(MAIN_LANGUAGE, languageVSet);
What if the interviewer doesn't pick any language in B15? Then our dynamic value set is empty. We should add a check to B15 to ensure that at least one language is chosen.
Dynamic Checkboxes
Let's implement a dynamic value set for question G2, "were assets purchased with a loan". Rather than a series of yes/no questions, we implement this using a single variable with checkboxes. We could have one checkbox for each of the 10 items in the assets roster but it would be better if we only displayed the checkboxes for the assets that the household actually possesses. How do we know if the household possesses an item? The household possesses the item if its quantity is greater than zero. We need to loop through the rows of the roster and add a checkbox to the value set for each item with quantity greater than zero. The only tricky part is that these are checkboxes so we need to use alpha values.In order to create a value set with alpha values we need declare a ValueSet object that accepts alpha codes.
ValueSet string possessionsVSet;
We build the value set in the onfocus of the checkboxes field. We use the alphabet string trick again to get the alpha codes from the occurrence number. We also use the function getocclabel() to get the occurrence label from the assets roster to use in the value set.
PROC POSSESSIONS_PURCHASED_WITH_LOAN
onfocus
// Create dynamic value set from assets that have quantity > 0
ValueSet string possessionsVSet;
string alphabet = "ABCDEFGHIJ";
do numeric assetNumber = 1 while assetNumber <= totocc(POSSESSIONS_ROSTER)
// Check if household possesses this asset
if QUANTITY(assetNumber) > 0 then
// Add to value set
string label = getocclabel(POSSESSIONS_ROSTER(assetNumber));
possessionsVSet.add(label, alphabet[assetNumber:1]);
endif;
enddo;
setvalueset($, possessionsVSet);
onfocus
// Create dynamic value set from assets that have quantity > 0
ValueSet string possessionsVSet;
string alphabet = "ABCDEFGHIJ";
do numeric assetNumber = 1 while assetNumber <= totocc(POSSESSIONS_ROSTER)
// Check if household possesses this asset
if QUANTITY(assetNumber) > 0 then
// Add to value set
string label = getocclabel(POSSESSIONS_ROSTER(assetNumber));
possessionsVSet.add(label, alphabet[assetNumber:1]);
endif;
enddo;
setvalueset($, possessionsVSet);
Exercises
- Add question text to questions B06 through B8. Use fills to include the name as we did in the examples.
- Add a new language, the language of your choice, to the CAPI text and to the dictionary. Translate the question text, labels and value sets questions B06-B08 into the new language.
- Add question text for section G and use the occurrence labels to fill in the name of the possessions in the quantity and value fields.
- In question B06 (date of birth) use a dynamic value set for the day based on the month (January: 1-31, February: 1-28, March: 1-31…) so that the interviewer cannot enter an invalid date like February 30 or April 31. Bonus if you can correctly handle leap years.
- For E08 (line number of mother of deceased) use a dynamic value set to list the names of all eligible women from the household roster.